Content from Introduction
Last updated on 2024-12-31 | Edit this page
Overview
Questions
- What is multidimensional media?
- What does the FAIR principles refer to?
- What type of infrastructure are available for collaborative research and using linking multidimensional data over the web?
- What do I need to do if I want to create stories with my own multidimensional linked data?
Objectives
- To understand multidimensional data, including how data is stored in various types of files.
- To be aware of what the FAIR principles are.
- To understand how Uniform Resource Locator allow to query webpages as well as more structured information.
- To get experience using a Virtual Research Environment.
The resource aims to support better understanding of multidimensional media available over the web which might serve various educational, research, as well as storytelling and audience engagement processes.
The resource focuses on stories in the fields of visual and material culture within Higher Education, Galleries, Libraries, Archives, Museums (GLAMs), as well as the creative industries. Hence, it contains many examples and websites in this area. However, many concepts are cross-disciplinary and can be applied to other areas as well as sectors.
Content from Types of Multidimensional Media
Last updated on 2024-12-31 | Edit this page
Multidimensional media is a term which covers various types of non-textual data. It is often used to refer to representational and derivative media created through digitisation processes or synthetic images produced via software. These processes often result in multi-part, multi-format and, often, large project files which describe the creation process.
We refer to media as multidimensional. This is because data experts structure information according to the dimensions used to store the data in the computer system.
For example, the name of one of your friends can be stored in a data type with 1-dimension:
John SmithMeanwhile, a table which stores the name of all your friends and their addresses will use a data type similar to a spreadsheet table.
| Name | Address |
|-----------------|-----------------|
| John Smith | 34 Street Rd |
| Marion Lopes | 105 Babel St |
The latter uses 2-dimensions as both rows and columns are used to organised the data.
Digital Images
Data in digital images is organised similar to tables, as pixels or picture element, which are the smallest element of an image, are organised across 2-dimensions. We usually refer to these dimensions as the x,y axis.
The image resolution usually refers to how many pixels an image has, either as a total or its width. This is why resolution is usually given in 2-dimensions, for example an image with a resolution of 800 × 600 pixels will have 800 pixels across the x-axis (its width), and 600 pixels across the y-axis (its height). The image will contain 480,000 pixels in total.

Meanwhile, the PPI or DPI (Pixels per Inch or Dots Per Inch) attributes of images refers to their pixel density. That is how many pixels there are in 1 inch (2.54 cm) in the display in which the image is rendered or in the printed image.

Example of digital images include digital photographs generated by a camera sensor (e.g. on a smart phone), or synthetic images created on directly on the computer (e.g. painting tools or generated by Artificial Intelligence software).


Given the wide-availability of camera sensors, including on smart phones and digital cameras, digital images are the widest available multidimensional media.
Image Platforms
Collections of images are found across many website, and popular search engines now support image-based search which allows to search digital-images across websites given an input image. See examples:
Challenge: Search for images
Save the image below and navigate in your browser to https://www.google.com/. Using the camera image on the search bar, search for the image.

Image Formats
Finally, images are commonly stored using formats such such as:
- JPEG, short for Joint Photographic Experts Group, and PNG Portable Network Graphics formats compress pixel information making the files size smaller.
- TIFF, short for Tag Image File Format, stores non-compressed information, making the file sizes larger.
Digital photography will make use of other formats, such as DNG or RAW to store raw image information. Other software store image projects in proprietary formats, meaning files can only be open by these.
Digital Video
Digital video could be considered a 2-dimensional or, even a 3-dimensional, type of media.
This is because a video contains many images or frames, which are stored in 2-dimensions as described above, and rendered sequentially.

Video also have a Resolution which is related to the images. Resolution will be the same for all the frames in a video file. For instance 4K video is usually made of frames which are X x Y in resolution.
The rate at which frames are displayed is usually referred to as Frames Per Second or FPS. For reference, TV and movies are usually displayed at 24 FPS.
Video Platforms
Video is also a popular type of content, as there are many platforms on the web which allow users to easily share their media. See examples:
Note that while images can be downloaded by web browsers, it is not always possible to download video from these websites. Many times, video is only made available through a media player.
Video Formats
There are many formats to store video and audio, including those supported by webpages:
- MP4 (MPEG-4) is a common container format which can play in almost all devices and over the web.
- WebM and OGG are open video formats.
There are many others formats.
Note that videos with higher resolution and FPS will be larger and hence, challenging to send via email or download over the web.
3D Images or Models
A 3D model is a 3-dimensional type of media. It describes 3D shapes along with other information related to its appearance, e.g. colour information.
To understand how 3D models are described and displayed in the computer, we need to understand two concepts vector and raster data.
In this lesson, we won’t cover how 3D models are created. There are resources here to learn more about processes:
- CARARE Introduction to the 3D workflow
- Photogrammetry
- Basic principles and tips for 3D digitisation of cultural heritage
Vector Data
Regardless of the process, the output of these processes, in most cases will produce a 3D model file which contains vector data.
This data include:
- Points or vertices described in a 3D space.
- Information on how the points are connected to form shapes such as triangles, which is known as the topology or connectivity of the 3D model.
- Colour or texture (image) information which describe its appearance.
Raster Data
Rasterisation is the process to go from a vector description into a raster image.
The raster image is the pixel-based representation of the vector description.
{kind=link}
3D models are rendered as raster images on the screen, smartphone or any other display device (e.g. a Virtual Reality headset). The computer will have to compute this raster image in real-time, which is why 3D models which contain many vertices can be slow to render.
Examples of 3D models
We tend to use 3D model to refer to many types of spatial data.
For example, see below an example of a 3D model of an architectural space.
© Trozzella from VisualMedia Service
In many cases, the 3D data can be mostly points in 3D space as shown below.
Spatial data can also be recorded with an additional parameter - time.
For instance, motion capture devices will generate vector data which changes many times within a second. We call this measure sampling rate per second.
© Motion Capture : Antonio d’Angelo / Effigy, 3D animated model from Sketchfab
3D Model Platforms
Popular format platforms include:
As with video, the viewers for 3D models normally allow to visualise and interact with the information. But not always does it allow to download the file.
3D Model Formats
There are many file formats for 3D images or models including:
- GLTF (JSON/ASCII) or GLB (binary) is the standard Graphics Library Transmission Format which is commonly used for 3D models on the web.
- OBJ, USD and PLY are popular format for 3D data which support additional information, such as textures or colour.
- STL is a popular format in 3D printing and rapid prototyping.
Other proprietary formats such as FBX and 3DS will contain vector information on scenes.
The number of points/vertices or triangles are used to determine the resolution of the 3D model. Note that, as with images and video, 3D models that have a larger number of vertices, for example, over 100,000 will have a larger size. This has an impact on how long it takes to download, load or render this content.
Gathering Multidimensional Files
Great variety of multidimensional content is available through the various platforms for research, education, entertainment and storytelling among other applications.
Some aggregation websites offer access to a variety of visual content, including:
Other discipline specific or museum sites include:
- Journal of Digital History Journal
- Brighton and Hove Museums
- Victoria and Albert Museum
- Science Group Museum
Some general advice when looking for content for your projects include:
- Download the multimedia file where possible and store locally or on the repository where you are curating the data set.
- Use the maximum resolution possible. It is always possible to reduce the number of pixels, but not to increase them.
- Record basic metadata about the file, including the reference and copyright to the image.
If you are doing additional research look at data models, such as Dublin-CORE cross domain set, which contains useful information to store, including:
- Title
- Subject
- Description
- Date
- Resource Type
- Format
- Resource Identifier
- Language
- Rights Management
This will become useful information to provide later as part of the data set. 4. Use a suitable file name to keep easy track of the media and its provenance. If the file it is too large, it is possible to resize and save again in medium and low quality.
For example:
WebsiteFromWhereFileWasDownloaded_ResourceID_[high|medium|low].[format] This will become:
Flick_photo1234_high.png
Flick_photo1234_medium.png
Flick_photo1234_low.pngKey Points
Digital Images are organized using pixels, the smallest elements of an image, which are arranged across 2 dimensions (x and y axis).
Image resolution refers to the number of pixels, and it is usually given in 2 dimensions (e.g., 800 × 600 pixels).
Digital Video is a 2-dimensional or even 3-dimensional type of media.
Videos consist of multiple frames stored in 2 dimensions (like images).
Videos also have a resolution and frame rate (Frames Per Second).
3D Images or Models are files containing vector data describing spatial information.
Rasterization is the process of converting vector graphics into raster images.
Various aspects need to be considered when collecting, storing, and managing multimedia files effectively.
Recording metadata and using appropriate file naming conventions is important.
Content from Uniform Resource Locators (URLs)
Last updated on 2024-12-31 | Edit this page
Delivering/retrieving multidimensional content over the web provides many advantages:
- Being able to easily access the content regardless of which platform they are using, such as PCs, mobiles or a VR headsets.
- Using common Internet interfaces and protocols (e.g. HTTP/HTTPs) to query, retrieve and display content.
Web Basics: Uniform Resource Locator
In order to understand how to provide access to multidimensional data over the web, it is first necessary to learn how data, of any type, is made available over the Internet.
A webpage is usually written in HTML and other web-languages, such as JavaScript, TypeScript or PHP. This code is in remote computers so that everyone can access the webpage they render.
To find webpages, we use a link on a browser called an URL (Uniform Resource Locator), such as https://www.brighton.ac.uk, https://www.europeana.eu/en.
URL Paths
Many web servers make use of the full URL path to send information to the server. A URL path usually specifies the location of the file or resource that the user wants to access in the server.
You will find this usually with images, PDF and other multimedia file that a webpage will be including. For example: https://culturedigitalskills.org/wp-content/uploads/Logo-Banner-3-1-1024x244.png
{kind=link}
URL Anchors
Furthermore, URLs can contain a link to a specific section within a web page by using anchors. You will notice the use of anchors on a URL, as they include using a # symbol followed by a word. This word is usually defined in the HTML code so that the webpage knows which part the user is looking for.
See these examples:
Challenge: Try this example
What is the difference of navigating to these two different URLs?
You will notice that the URL that contains the # symbol in the URL takes you to the specific section with the 17 SDG goals.
URL Query String (or Query Text!)
URLs can become more complex if we want the server which is ‘serving’ our webpage to perform any additional functionality before, during or after loading the webpage.
The ? symbol in a URL is known as URL parameter or query string.
The query string is the portion of text which comes after the ? symbol.
This text will be passed as data to the server.
The server might be running additional code which will process this text and change the content of the webpage accordingly.
For example, in the query
https://www.google.com/search?q=news&as_sitesearch=www.brighton.ac.uk&sort=date:D:S:d1
Note that you have three parameters:
- q: the search query.
- as_sitesearch: limits search results to documents in the specified domain, host or web directory.
- date: Sort results in descending order by date.
If the text or strings contains more than one word, the spaces should be replaced by the + symbol. For example:
More information about parameters for search: https://www.google.com/support/enterprise/static/gsa/docs/admin/current/gsa_doc_set/xml_reference/request_format.html
Challenge: Use a query in a URL
Try searching a word in the Europeana homepage.
For example, search for the word: ‘modernism’
Try using the query text in the Europeana URL to search for the word modernism:
https://www.europeana.eu/en/search?page=1&view=grid&query=modernism
Now, try changing directly the search term to the URL to a phrase.
Go back to the Europeana homepage.
Query strings are also used by Application Programming Interfaces or (APIs). In this lesson, we won’t explore this subject in detail. But it will be good you are aware that the information is passed to the server via the URL path.
For example, try the URL:
https://gtr.gtr.ukri.org/gtr/api/projects/5B805CC1-2B54-4CAE-9243-8EF4AFC35E7E
This URL queries an API (or database running on the server) to retrieve information that is contained in the database about the AHRC funded project ‘A Roadmap for a National Training Centre on Multidimensional Digital Media in the Arts and Humanities’. As you will see in the webpage, the information is not an HTML page but another structured type of data which contains various pieces of information about the project.
To understand how to use these URL, you usually need the guide to the API. For example, the query specified above users the database of the Gateway to research guide.
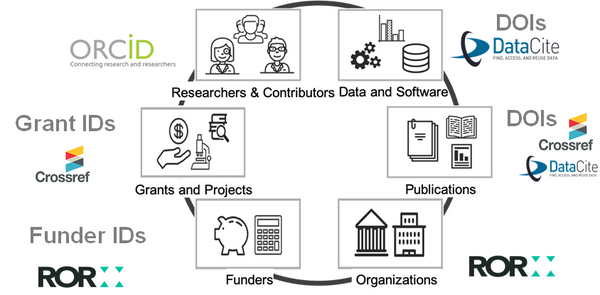
Persistent Identifiers (PIDs)
Although URLs are useful to retrieve a webpage, they are often not permanent.
URLs might stop working after a project finishes or funding ends to maintain a website.
Persistent identifiers (PIDs) address this challenge by ensuring the link to a digital object continue to exist in the long term.
The PID is a unique identifier that represents a something with a number or code.
They are similar to ISBN and ISSN which were used by publishers to identify written texts.
Currently there are PIDs to identify:
- Contributor, inc. authors and researchers
- Data and Software, inc. data sets, tables, figures, videos, code, 3D models
- Publications, inc. books, articles, white papers, chapters
- Projects, inc. grants given by funders
- Organization, inc. institutions, funders, corporations, government agencies
Key Points
- URLs can be a simple means to find a website.
- URLs can also include additional information which allows a server to change how the webpage is ‘served’.
- Anchors allow to easily jump to part of the page.
- URLs also provide the means to use a website as a database which can be queried via the URL path.
Content from Making it FAIR
Last updated on 2024-12-31 | Edit this page
Making it FAIR
Emphasis should be placed in following the FAIR principles when creating multidimensional data or bringing together existing data within a project/initiatives.
FAIR refers to the following actions which should be promoted.
Findability

“The first step in (re)using data is to find them. Metadata and data should be easy to find for both humans and computers. Machine-readable metadata are essential for automatic discovery of datasets and services…” https://www.go-fair.org/fair-principles/
Data should be linked to rich and structured metadata.
Where possible this should be made accessible through a searchable resource such as an aggregation platform.
Data should be accessible through a persistent identifiers (which do not change over time). For example, DOIs can be assigned to data through platforms such as Zenodo or Github.
Accessibility

The user “need to know how they can be accessed, possibly including authentication and authorisation”. https://www.go-fair.org/fair-principles/
Metadata should be accessible via using a protocol for web, such as HTTP/HTTPS which allows to access a webpage over the browser or query a database through a service known as Application Programming Interface (API).
Where necessary, the protocol show allow for authentication and authorization to enforce data management rights.
Consider who will be excluded from access the data, for instance if this is only available via an institutional platform or in a particular language.
Interoperability

“The data usually need to be integrated with other data. In addition, the data need to interoperate with applications or workflows for analysis, storage, and processing.” https://www.go-fair.org/fair-principles/
- Consider how other users will bring together content from various data sets, for instance to create a new project.
- For visual media, including images, video and 3D, IIIF (generally pronounced “triple-eye-eff”) supports its interoperability of across websites and institutions.
- This framework allows to provide access and shared link to a file, as well as its (meta)data .
- When implemented across many institutions overcomes data silos.
For example, through IIIF it is possible to bring together objects which physically might be in different locations. It does not require a user to download the files but simply to access the files and metadata over the web.
Reuse

“The ultimate goal of FAIR is to optimise the reuse of data.” https://www.go-fair.org/fair-principles/
Multidimensional data should be released with a clear and accessible data usage license.
Provenance data will help for data to not become lost.
CARE data principles
In addition, a series of principles known as CARE have been proposed by the Global Indigenous Data Alliance.
These principles include: Collective Benefit, Authority to Control, Responsibility, and Ethics.
Their focus on enhancing these principles by leveling power relationships where data is created within certain social and historical context.
Challenge: CARE principles for your data practice
Could you reflect on what implications following the CARE principles has for your personal practice when creating, collecting and using data.
For more information:
- Carroll, S.R., Garba, I., Figueroa-Rodríguez, O.L., Holbrook, J., Lovett, R., Materechera, S., Parsons, M., Raseroka, K., Rodriguez-Lonebear, D., Rowe, R., Sara, R., Walker, J.D., Anderson, J. and Hudson, M., 2020. The CARE Principles for Indigenous Data Governance. Data Science Journal, 19(1), p.43.DOI: https://doi.org/10.5334/dsj-2020-043
- Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
Key Points
| Principle | Key Points |
|---|---|
| Findability | - Available metadata - Allow for searchability - Persistent IDs |
| Accesibility | - Use web protocols for access - Allow for authorisation - Digital inclusion/exclusion |
| Interoperability | - Data integration - Overcomes data silos - IIIF for visual media |
| Reuse | - License content - Avoid data becoming lost |
Content from Virtual Research Environment
Last updated on 2024-12-31 | Edit this page
To enable collaboration and open access as well as open science practices, it is recommended to manage the multidimensional media in a way which is accessible to the team you are working with and with others who might benefit from the effort you have done to curate the data.
There are some web-platforms which can easily allow this, such as document management and storage system, e.g.
All these enable sharing capabilities with people within and beyond your organisations.
Other systems such as Virtual Research Environments are also available for sharing data with the same community of practice.
Virtual Research Environments (VRE)
VREs make it easy for teams across organisations to collaborate in data-driven research process. We will use D4Science in this lesson.
For example, a project that you are developing with friends/colleagues might involve investigating how it was living in Brighton in the 18th century. You might be using this to recreate visually a scene in the city.
Visual information can make it easier to develop the project, and it can also be more engaging for users to feedback on early prototypes.
Information can include:
- Mapping the geographical areas which were inhabited in Brighton as well as any roads.
- What architecture did larger and smaller buildings had?
- How did people dress?
- What activities they did?
To enable collaboration and support FAIR principles, Virtual Research Environments (VRE) can be useful. VREs are collaborative environments created on-demand allowing remote sharing of applications, services and data resources.
We will make use of D4Science to explore further these environments.
Either click on the link or copy/paste to your browser the address: https://services.d4science.org/group/d4science-services-gateway/explore.
Login by using your existing login credentials, e.g. the one of your institution or your Google account.
You will see the main interface upon successful login. See below.
The VRE offers the following capabilities:
- Workspace: enables members to store and share data securely.
- Mailing System and Forum: enable members to community one-to-one or as a community.
- Data Analytics: enable members to access cloud computing facilities to collaborate in developing and applying data-algorithms.
To test some of these access in the main interface, the menu bar at the top showing the Workspace and an Analytics menu items. Click on any of them to access this functionality.
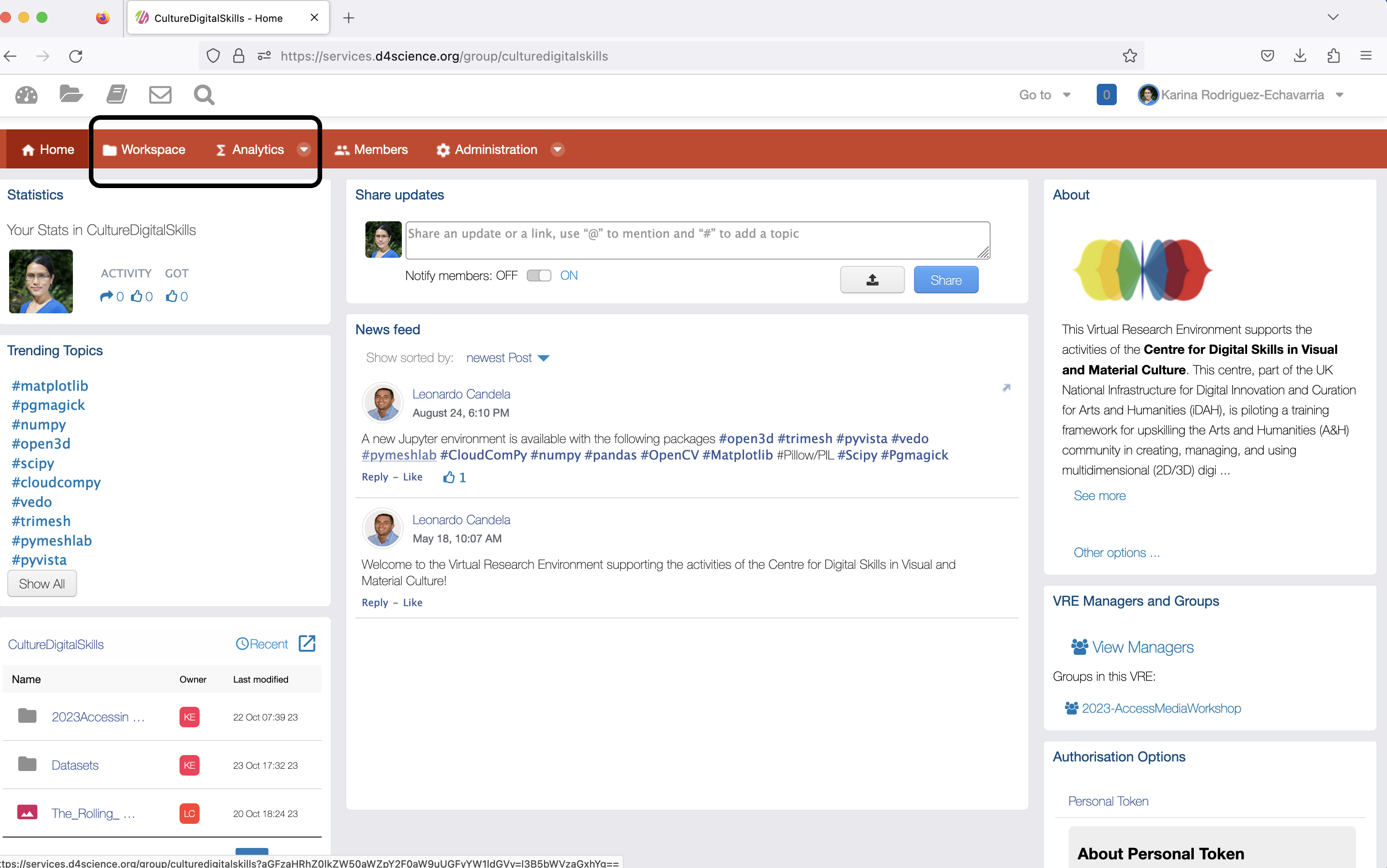
Click on Workspace.
Workspace
The workspace allows a member to create and share folder, as well as upload files.
It facilitates on-line file sharing across organisations.
Folders and data can be shared with all or specific users of the VRE.
Testing the Workspace: Upload a file
Using what you have learned on downloading media, access an example of an image from a repository from your institution or a project.
If you don’t have any, use the following from Wikimedia:

{kind=link}
Create a folder in your workspace, upload the image and share with another person in the group.
The functionality that the workspace provides include:
- Preview the file.
- Get basic information - note that vary basic metadata, such as name, ID, and type are supported. There is a description field which allows for recording additional metadata.
- Version number, as the owner of a file can replace the file keeping the older versions to facilitate version control.
- Searchable link to the file.
- History of operations performed by users to the file.
- Move to another folder.
- Make a copy to another folder.
- Rename and Delete the files.
- Show and Download to the local computer.
VRE Analytics
VREs also provide access to an interactive development environment for Notebooks, code, and data. For this, the VRE provides access to a JupyterLab enviornment. It supports over 40 programming languages, including Python, Java, R, Julia, and Scala.
The Notebooks environment are increasingly used by researchers where they can combine text, mathematics, computations and rich media output. It requires of a special language for formatting text known as markup.
The environment also support basic editing of text-data and the implementation of data processing algorithms using high-performance back end computers.
Challenge
Access JupyterLab in the Analytics menu. Select one of the options for accessing a virtual server.
This will create a ‘virtual’ machine.
You should find a Navigate to the folder where you created by clicking on the folder icon on the left menu.
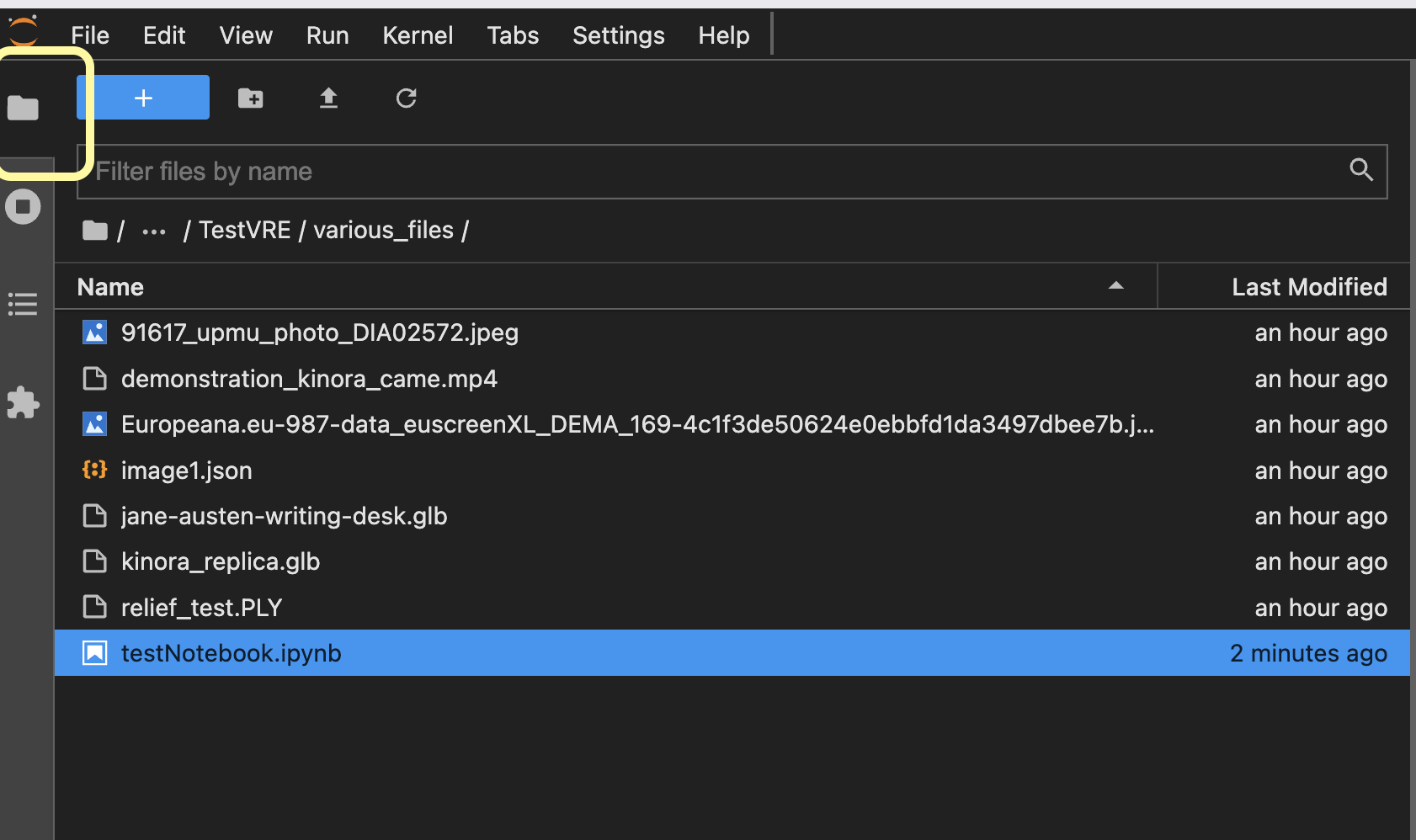
Create a new Text file, by clicking on the + icon, and selecting Other -> Text File.
Change its name and save it.
Key Points
Multidimensional media requires good management, to underpin collaboration and open access/science processes.
Virtual Research Environments (VREs) are collaborative spaces for data-driven research.
VREs offer workspaces for secure data storage, mailing systems, forums, and data analytics capabilities.
Content from Retrieving and Curating Multidimensional Data
Last updated on 2024-12-31 | Edit this page
We will curate a data set of multidimensional data to practice what we learnt.
We will make use of the VRE to store, collaborate and provide access to the data set.
Challenge: Curating dataset
In teams of 2-3 choose a theme to retrieve and curate the data set.
The theme can be either a project you are developing, or you can choose one from the ones described below.
If you have selected a theme in previous sessions, e.g. previous tutorial, you can continue working on this.
Search for a minimum of 5-6 images, a video and a 3D image/model. Downloaded them and upload to a share folder in the VRE. Take care of your resolution, file names, and recording the metadata of the files.
Digital storytelling suggested themes
Industrial heritage
Stories: https://www.europeana.eu/en/stories?tags=industrial-heritage&page=1
3D data: https://www.europeana.eu/en/search?page=1&qf=TYPE%3A%223D%22&qf=collection%3Aindustrial&query=&reusability=restricted&view=grid
https://sketchfab.com/search?category=cultural-heritage-history&features=downloadable&licenses=7c23a1ba438d4306920229c12afcb5f9&licenses=322a749bcfa841b29dff1e8a1bb74b0b&q=industrial&type=models
Crafts
Stories: https://www.europeana.eu/en/stories?tags=crafts
3D data: https://sketchfab.com/search?category=cultural-heritage-history&features=downloadable&licenses=322a749bcfa841b29dff1e8a1bb74b0b&licenses=7c23a1ba438d4306920229c12afcb5f9&q=craft&type=models https://www.europeana.eu/en/search?page=1&qf=TYPE%3A%223D%22&query=%22Craft%22&reusability=restricted&view=grid
Photography
Stories: https://www.europeana.eu/en/stories?tags=photography
Fashion
Content from Interoperable Frameworks
Last updated on 2024-12-31 | Edit this page

What is IIIF?
There is a key need for accessing and interacting with multidimensional media over the web: allowing users to easily use/reuse multidimensional content by accessing it from its existing hosting site.
The International Image Interoperability Framework (IIIF) is a community of software, tools, content, people, and institutions solving image Interoperability challenges.
It provides a set of technical specifications built around shared challenges for accessing multidimensional media.
IIIF has the following goals1:
- To give users an unprecedented level of uniform and rich access to media-based resources hosted around the world.
- To support interoperability between media repositories.
- To develop, cultivate and document shared technologies, such as image servers and web clients, that provide a world-class user experience in viewing, comparing, manipulating and annotating images.
The IIIF technical specifications are the glue that holds things together for image interoperability.
IIIF provides various core APIs:
- Image API (I want to get image pixels)
- Presentation API (I want to display the images)
- Content Search API
- Authentication API
This workshop will focus on the Image and Presentation APIs.
Image API
The Image API provides for a standardized way to request and deliver images. This can be for example:
- Give me the original image at full resolution.
- Give me the original image at low resolution.
- Give me a small section at the centre of the image.
- Give me an upside down tiled version of the image in gif format.
The IIIF Image API allows for images to be served dynamically or from a static cache (implementation details).
Images are requested using URI templates that have the following syntax:
{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}Here is a quick example of how modifying these parameters can change the image that is delivered back to you.
For example, the image below is of dimensions 300 by 200 pixels.

The image API allows to retrieve an image containing a region of the image. This requires using a URL which contains the region as defined by:
- Top-left coordinates: 125,15 which means 125 in the x direction, and 15 in the y direction
- Size of the box: 120 in the x direction and 140 in the y direction.

It is also possible to define the size (e.g. 90), rotation and quality required. All this information can be expressed as:
region=125,15,120,140 size=90, rotation=0 quality=color
.../125,15,120,140/90,/0/color.jpg
# Source: https://iiif.io/api/image/3.0/Options for quality include: default, color, gray and bitonal.
Trying the Image API
For the following image in an Image API Service:

Task 1: Write a URL on the browser that has the following parameters:
region=800,300,500,500
size=200,
rotation=90
quality=color
Task 2: Write a URL on the browser that has the following parameters:
region=500,1000,400,300
size=max
rotation=0
quality=gray
To create the url, you will need to combine the information according to the following url guidance:
{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}Using the following information:
- scheme: https
- server: 6fzwqjk2sg.execute-api.eu-west-2.amazonaws.com/
- prefix: latest/iiif/2/
- identifier: Johannes_Vermeer_Het_Melkmeisje/
- region: 800,300,500,500
- size: 200,
- rotation: 90
- quality: color
- format: .jpg
{kind=link}
- scheme: https
- server: 6fzwqjk2sg.execute-api.eu-west-2.amazonaws.com/
- prefix: latest/iiif/2/
- identifier: Johannes_Vermeer_Het_Melkmeisje/
- region: 500,1000,400,300
- size: max
- rotation: 0
- quality: gray
- format: .jpg
{kind=link}
Presentation API
The IIIF Presentation API is based on linked-data and enables you to make accessible a JSON file, which is a standard text-based format for representing structured data, known as the IIIF Manifest.
The IIIF Manifest describes a structured layout for presenting the multidimensional media and their metadata, including information such as:
- Labels
- Description
- License
- Attribution
- Link to the file
The IIIF Manifest can be read by a IIIF Viewer to present this multidimensional media. Existing Viewers include:
- Universal Viewer: https://universalviewer.io/
- Mirador: https://projectmirador.org/
See some examples of IIIF Manifests for various IIIF Organisations, including amongst others:
- Wellcome Library
- V&A
- British Library
- Bodleian
IIIF Manifest Example
Various heritage institutions are making available IIIF manifest in from their collection web access pages.
For example:
- Getty provides access to IIIF Manifest when browsing items in their collection. See example: https://www.getty.edu/art/collection/object/107DZP contains the JSON code which is web-accessible.
Note that all these metadata can be accessed and made available through the Viewer:
© J. Paul Getty Trust, licensed under CC BY 4.0.
Another example is the The University of Edinburgh Collections web-accessible Mahabharata Scroll which showcases the advantages of the IIIF Presentation API for artefacts which are not easily accessible or cannot be handled.
IIIF Manifest Structure
See below an example of a IIIF Manifest written in JSON:
JSON
{
"@context": "http://iiif.io/api/presentation/3/context.json",
"id": "https://iiif.io/api/cookbook/recipe/0001-mvm-image/manifest.json",
"type": "Manifest",
"label": {
"en": [
"Single Image Example"
]
},
"items": [
{
"id": "https://iiif.io/api/cookbook/recipe/0001-mvm-image/canvas/p1",
"type": "Canvas",
"height": 1800,
"width": 1200,
"items": [
{
"id": "https://iiif.io/api/cookbook/recipe/0001-mvm-image/page/p1/1",
"type": "AnnotationPage",
"items": [
{
"id": "https://iiif.io/api/cookbook/recipe/0001-mvm-image/annotation/p0001-image",
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "http://iiif.io/api/presentation/2.1/example/fixtures/resources/page1-full.png",
"type": "Image",
"format": "image/png",
"height": 1800,
"width": 1200
},
"target": "https://iiif.io/api/cookbook/recipe/0001-mvm-image/canvas/p1"
}
]
}
]
}
]
}From: IIIF Cookbook recipes: https://iiif.io/api/cookbook/recipe/0001-mvm-image/
Note that it contains the following information:
- Context: Tells how to interpret the information.
- ID: Unique identifier.
- Type: Whether it is a Manifest or other type of JSON file.
- Label: A human readable label, name or title for the resource.
- Canvas: An individual page. This is the container where the multidimensional media is going to be drawn. It has some properties such as width and height, as well as the items which will be drawn on it.
- Annotation Page and Annotation: instructs to present the image as (part of) the Canvas.
- Target: The Canvas where the media asset should be drawn.
The IIIF Manifest is not normally written by hand. Instead it can be done using a script, or using a tool such as a Manifest Editor:
- Bodleian Libraries Manifest Editor: https://digital.bodleian.ox.ac.uk/manifest-editor
- Digirati Manifest Editor: https://manifest-editor.digirati.services/
More Resources and References
- IIIF resources, see: https://iiif.io/guides/finding_resources/.
- Information on how to put together a JSON file, see: https://iiif.io/api/presentation/3.0/
- More information: Everything you ever wanted to know about IIIF but were too afraid to ask.
Content adopted from IIIF Training © IIIF under CC-BY-4.0
From http://iiif.io/about/:↩︎
Content from Storytelling with Mutltidimensional Media
Last updated on 2024-12-31 | Edit this page
During this exercise you will curate a story bringing together multidimensional media using Exhibit tool.
The example below shows a story of the Kinora, which was an early motion picture device developed by the French inventors Auguste and Louis Lumière in 1895.
The story brings together images, videos and 3D models to illustrate the history of these artefacts, their context and mechanics. The media with which this story as developed is available here.
You can also view the story here: https://www.exhibit.so/exhibits/zrHKbV2wqdpcRyfVW05M
Developing a story in Exhibit
Using the dataset of multidimensional data which you previously curated, the task is to create a story which brings all of this together.
Use the tutorial Exhibit website: https://exhibit-culturedigitalskills.vercel.app/
You will need to register to use the tool.
More instructions on creating an Exhibit are here: https://exhibit-culturedigitalskills.vercel.app/docs
IIIF content
You can upload files for images and 3D models, or use existing IIIF content with Exhibit.
If you would like to use a IIIF Manifest, you can use a tools such as Digirati Manifest Editor.
Create the JSON file using the editor, and upload it alongside the media content in D4Science. Then you can provide this JSON url to Exhibit.
To create the JSON, use the following JSON files as examples. Pasting the URL links to the in the Digirati Manifest Editor interface:
- Image: https://data.d4science.org/shub/E_RjlleHRKM1A3TTUzR0ZiYW1vcjFtNWVyY0JPTzU0djdDNzMrV09LMWgzenF4K0lYc0MzNnZud3BNSHZrK3ZWdQ==
- Video: https://data.d4science.org/shub/E_em1ReGc4cE13N2NPYTJrRXUwS3BEbTJqMU5RSEx5cFZ5aXZTRUJ0MDVDdTNsMk5PaUhGOVRmL0FwSThHdmNHNQ==
- 3D model: https://data.d4science.org/shub/E_djREWnFmY1BMS0FJSDh2cTBPQXUwc090NmpldmR3QkNyRWxmN0RvWFZQWWN2TG5OMFM1cWJocWxXNm85dUdYUA==

Content from Links
Last updated on 2024-12-31 | Edit this page
Summary of sites with multidimensional assets:
Images:
Videos:
3D Model:
Other datasets:
Publication Journals:
Other: