Uniform Resource Locators (URLs)
Last updated on 2024-12-31 | Edit this page
Delivering/retrieving multidimensional content over the web provides many advantages:
- Being able to easily access the content regardless of which platform they are using, such as PCs, mobiles or a VR headsets.
- Using common Internet interfaces and protocols (e.g. HTTP/HTTPs) to query, retrieve and display content.
Web Basics: Uniform Resource Locator
In order to understand how to provide access to multidimensional data over the web, it is first necessary to learn how data, of any type, is made available over the Internet.
A webpage is usually written in HTML and other web-languages, such as JavaScript, TypeScript or PHP. This code is in remote computers so that everyone can access the webpage they render.
To find webpages, we use a link on a browser called an URL (Uniform Resource Locator), such as https://www.brighton.ac.uk, https://www.europeana.eu/en.
URL Paths
Many web servers make use of the full URL path to send information to the server. A URL path usually specifies the location of the file or resource that the user wants to access in the server.
You will find this usually with images, PDF and other multimedia file that a webpage will be including. For example: https://culturedigitalskills.org/wp-content/uploads/Logo-Banner-3-1-1024x244.png
{kind=link}
URL Anchors
Furthermore, URLs can contain a link to a specific section within a web page by using anchors. You will notice the use of anchors on a URL, as they include using a # symbol followed by a word. This word is usually defined in the HTML code so that the webpage knows which part the user is looking for.
See these examples:
Challenge: Try this example
What is the difference of navigating to these two different URLs?
You will notice that the URL that contains the # symbol in the URL takes you to the specific section with the 17 SDG goals.
URL Query String (or Query Text!)
URLs can become more complex if we want the server which is ‘serving’ our webpage to perform any additional functionality before, during or after loading the webpage.
The ? symbol in a URL is known as URL parameter or query string.
The query string is the portion of text which comes after the ? symbol.
This text will be passed as data to the server.
The server might be running additional code which will process this text and change the content of the webpage accordingly.
For example, in the query
https://www.google.com/search?q=news&as_sitesearch=www.brighton.ac.uk&sort=date:D:S:d1
Note that you have three parameters:
- q: the search query.
- as_sitesearch: limits search results to documents in the specified domain, host or web directory.
- date: Sort results in descending order by date.
If the text or strings contains more than one word, the spaces should be replaced by the + symbol. For example:
More information about parameters for search: https://www.google.com/support/enterprise/static/gsa/docs/admin/current/gsa_doc_set/xml_reference/request_format.html
Challenge: Use a query in a URL
Try searching a word in the Europeana homepage.
For example, search for the word: ‘modernism’
Try using the query text in the Europeana URL to search for the word modernism:
https://www.europeana.eu/en/search?page=1&view=grid&query=modernism
Now, try changing directly the search term to the URL to a phrase.
Go back to the Europeana homepage.
Query strings are also used by Application Programming Interfaces or (APIs). In this lesson, we won’t explore this subject in detail. But it will be good you are aware that the information is passed to the server via the URL path.
For example, try the URL:
https://gtr.gtr.ukri.org/gtr/api/projects/5B805CC1-2B54-4CAE-9243-8EF4AFC35E7E
This URL queries an API (or database running on the server) to retrieve information that is contained in the database about the AHRC funded project ‘A Roadmap for a National Training Centre on Multidimensional Digital Media in the Arts and Humanities’. As you will see in the webpage, the information is not an HTML page but another structured type of data which contains various pieces of information about the project.
To understand how to use these URL, you usually need the guide to the API. For example, the query specified above users the database of the Gateway to research guide.
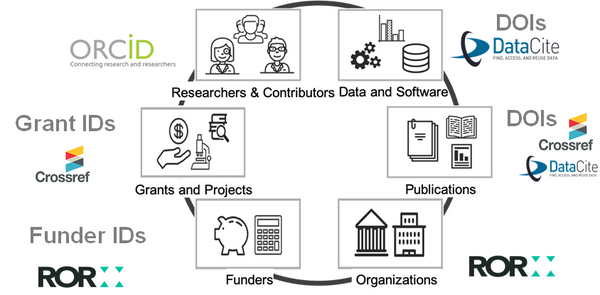
Persistent Identifiers (PIDs)
Although URLs are useful to retrieve a webpage, they are often not permanent.
URLs might stop working after a project finishes or funding ends to maintain a website.
Persistent identifiers (PIDs) address this challenge by ensuring the link to a digital object continue to exist in the long term.
The PID is a unique identifier that represents a something with a number or code.
They are similar to ISBN and ISSN which were used by publishers to identify written texts.
Currently there are PIDs to identify:
- Contributor, inc. authors and researchers
- Data and Software, inc. data sets, tables, figures, videos, code, 3D models
- Publications, inc. books, articles, white papers, chapters
- Projects, inc. grants given by funders
- Organization, inc. institutions, funders, corporations, government agencies
Key Points
- URLs can be a simple means to find a website.
- URLs can also include additional information which allows a server to change how the webpage is ‘served’.
- Anchors allow to easily jump to part of the page.
- URLs also provide the means to use a website as a database which can be queried via the URL path.